„Intel Skylake“ procesoriai galimai turi užslėptą savybę – atbulinį Hyper-Threading
„Intel“ galimai užlaikė vieną didesnių naujienų susijusių su jų „Skylake“ architektūrą turinčiais procesoriais. Manoma, kad naujausi „Intel“ gaminiai turi atbulinę Hyper-Threading technologiją, t.y. geba dauguma savo resursų panaudoti vienai gijai.
Tokia prielaida susidarė po „Heise.de“ išplatinto bandymo, kuriame neseniai pristatytas „Skylake-S“ procesorius tiesiog sutraiško pirmtaką vienos gijos užduotyje. Didėjant gijų skaičiui „Core i7-6700K“ pranašumas prieš „Core i7-4790K“ mažėja. Tai matyt vyksta dėl to, kad net su viena gija naujesnę architektūrą turintis procesorius dirba gana intensyviai, o davus papildomo darbo laisvų resursų yra mažiau nei jų turi „Haswell“ procesorius.
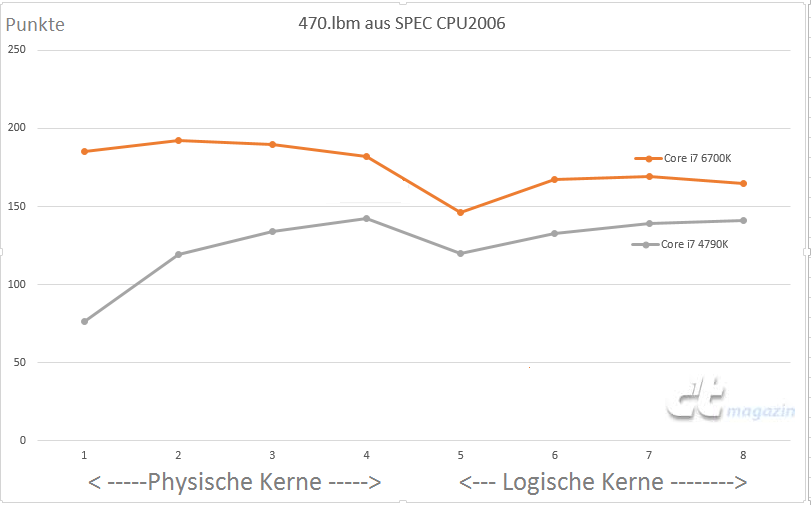
Manoma, kad panaudojus tokią technologiją, kai procesorius su viena gija geba panaudoti daugelį savo resursų, sparta gali išaugti 2-4 kartus lyginant su procesoriumi neturinčiu šios naujovės, ką mums ir parodė atliktas bandymas.
Tikėkimės, kad apie šią inovaciją „Intel“ plačiau papasakos savo IDF renginyje vyksiančiame rugpjūčio 18-20 dienomis San Franciske.

Va cia tai naujiena 🙂
Manau tik vienas minusas šios naujovės, ji pas mus atkeliavo stipriai per vėlai. Nors žiūrint į ateiti, kai pagaliau gausim daugiau branduolių, tokia techologija tikrai pravers.
Bet kas yra svarbiausia, Intel oficialaus pranešimo kiek žinau šia tema nėra padariusi, kažkaip keista, kad užlaikė tokia naujieną.
Na, jei čia iš tikro tiesa, tai tada į skylake tikrai labai verta atsinaujinti ir išnaudoti visus branduolius tinkamai. 🙂
Prie to pacio, neblogas Skylake spartos padidejimas perejus nuo win8.1 prie win10:
http://www.tomshardware.com/reviews/skylake-intel-core-i7-6700k-core-i5-6600k,4252-5.html
o čia visai mistika… instrukcijos? Šiaip čia labiau nuo OS priklauso ir taip būtų su bet kuriuo procesoriumi and win 10.
Jūs patys suprantat, kas per žvėris tas HT yra? Toks dalykas "atbulomis" yra iš principo neįmanomas.
Gal ir neimanomas, as tau ne lituanistas. Duok savo varianta.
Isversta viskas gerai, sako is principo, kad neimanoma… Jeigu tai butu tiesa, tai buldozeriai turejo skraidyt… 😀
Va ko gero arčiausiai tokio dalyko esantis reikalas yra aprašytas čia http://hps.ece.utexas.edu/pub/morphcore_micro2012.pdf
Jei jie tai realiai būtų sukūrę tai mes žinotume dar prieš paleidžiant CPU į prekybą, nes skambintų visais varpais.
O tokio atbulinio HT gandai savo ištakas turi berods dar tuose laikuose kai Intelis AMD ragus aplaužė su Core 2 Duo. Greičiausiai kažkoks fanbojus leptelėjo tokią nesamonę internetuos ir kažkas kas keli metai pakartoją tai.
Dar toks dalykas kaip VISC yra, kuris neva sugeba priversti dirbti proco resursus esant vienai gijai. Kažkoks jų spaudos pranešimas yra iš 2014 metų, bet aš iki šio straipsnio nieko apie juos nebuvau girdėjęs. http://www.softmachines.com/soft-machines-unveils-visc-microprocessor-architecture-breakthrough-revives-performance-per-watt-scaling/
http://wccftech.com/intel-inverse-hyper-threading-skylake/
Ech, aš jau buvau susiradęs, kad sourcas wccftech 😀 Žodž, biški skeptiškai aš vertinu ką jie rašo. Dar biški google-fu pavariau ir realestiškenis (mano galva) variantas yra, kad vėl buvo padaryta kažkas panašaus kaip sandy bridge -> ivy bridge
Some structures within the chip are now better optimized for single threaded execution. Hyper Threading requires a bunch of partitioning of internal structures (e.g. buffers/queues) to allow instructions from multiple threads to use those structures simultaneously. In Sandy Bridge, many of those structures are statically partitioned. If you have a buffer that can hold 20 entries, each thread gets up to 10 entries in the buffer. In the event of a single threaded workload, half of the buffer goes unused. Ivy Bridge reworks a number of these data structures to dynamically allocate resources to threads. Now if there’s only a single thread active, these structures will dedicate all resources to servicing that thread. One such example is the DSB queue that serves the uOp cache mentioned above. There’s a lookup mechanism for putting uOps into the cache. Those requests are placed into the DSB queue, which used to be split evenly between threads. In Ivy Bridge the DSB queue is allocated dynamically to one or both threads.
http://www.anandtech.com/show/4830/intels-ivy-bridge-architecture-exposed/2
EDIT:Būūūū, kodėl teksto formatavimas neveikia
Va dar šiek tiek senesnių dalykų panašiai į temą
Anaphase – http://newsroom.intel.com/docs/DOC-1111
Mitosis – http://www.dvhardware.net/article6594.html
Man atrodo, kad toks dalykas visgi padaromas, bet ar Intel sugalvotų tokia naujovę slėpti, tuo labai abejoju.
Na pasikarsčiavau, galbūt galutinis rezultatas ir pasiekiamas, bet tai nėra padaryta Skylake. Tam reiktų ir naujos arch (pvz. VISC, kaip pats rodei) ir naujos OS.
Ne blogai, tik tiek, kad nemanau, jog verta atsinaujinti tiems, kas turi „Haswell“ procesorius. Nes tektų keisti: motininę, atmintį ir procesorių. Šita savybė – labiau pliusas, kurie dėliosis naują PC. 🙂
Zinot kaip atrodo masininis kodas? Prisiminkit tiuringo masina. Realiai vienos gijos neina skaiciuoti ant keliu branduoliu. Nebent naudoti spejimus arba kitokia magija. Pats kodas turetu buti sukompiliuotas i kazkokia magiska busena. Realiai kad viena gija skaiciuotu keli branduoliai, jie turi atspeti ateiti. Gal tas naujas HT tiesiog geriau duomenis paduoda. Nes cia butu nobelio vertas variantas. Kokio nobelio, simto Nobeliu premiju. Cia butu kaip zmogu i marsa nusiusti pirmyn ir atgal
Tokiu atveju pirminiais skaiciais paremtus raktus super kompai per akimirka nulauztu.