Naujas NVIDIA dirbtinio intelekto įrankis leidžia kurti mažesnius lustus
Projektuodami integruotas grandines lustuose inžinieriai siekia sukurti efektyvų dizainą, kurį būtų lengviau gaminti. Jei jiems pavyksta sumažinti grandinės dydį, didėja ir jos gamybos ekonomiškumas. NVIDIA savo techniniame tinklaraštyje paskelbė metodą, kuriame bendrovė naudoja dirbtinio intelekto modelį, vadinamą „PrefixRL“. Pasitelkdama gilųjį sustiprintąjį mokymąsi, NVIDIA naudoja „PrefixRL“ modelį, kad pranoktų tradicines EDA (elektronikos projektavimo automatizavimo) priemones iš kitų gamintojų, tokių kaip „Cadence“, „Synopsys“ ar „Siemens“ / „Mentor“. EDA pardavėjai paprastai diegia savo vidinį dirbtinio intelekto sprendimą silicio išdėstymui ir maršrutizavimui (PnR), tačiau panašu, kad NVIDIA sprendimas „PrefixRL“ daro stebuklus.
„PrefixRL“ tikslas – sukurti gilų mokymosi pastiprinimo modelį, kuriuo siekiama, kad vėlinimas išliktų toks pat, kaip ir EDA PnR bandymas, ir kartu būtų pasiektas mažesnis matricos plotas. Kaip rašoma techniniame tinklaraštyje, naujausioje „Hopper H100“ lusto architektūroje naudojama 13 000 aritmetinių grandinių egzempliorių, kuriuos sukūrė „PrefixRL“ dirbtinio intelekto modelis. NVIDIA sukūrė modelį, kuris pateikia 25 % mažesnes grandines nei palyginama EDA produkcija. Visa tai pasiekta užtikrinant panašų arba geresnį vėlinimą. Toliau galite palyginti „PrefixRL“ sukurtą 64 bitų dizainą ir tą patį dizainą, sukurtą pirmaujančia EDA priemone.
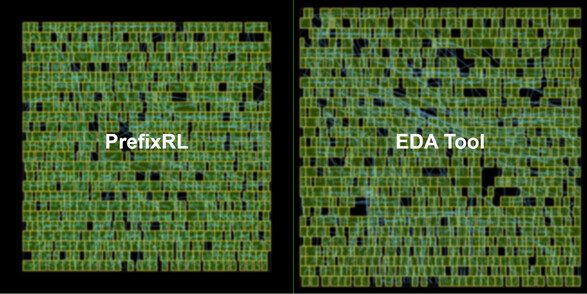

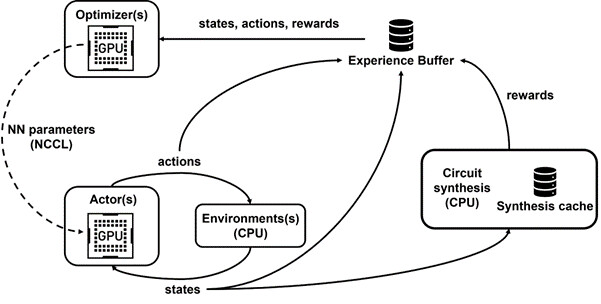
Tokio modelio apmokymas yra daug skaičiavimų reikalaujanti užduotis. NVIDIA praneša, kad 64 bitų grandinei suprojektuoti prireikė 256 procesoriaus branduolių kiekvienam grafikos spartintuvui ir 32 000 grafikos darbo valandų. Apskritai sistema yra gana sudėtinga ir reikalauja daug techninės įrangos ir sąnaudų; tačiau rezultatai atsiperka naudojant mažesnius ir efektyvesnius grafikos procesorius.

px tas dydis tegul geriau tam AI idiegia funkcija kad padarytu ir el sanudas kuo mazesnes o ne kuo didesnes kaip dabar yra 😀
Sąnaudos kyla, nes nori padaryti greitesnius lustus nei įprastai. Marketingas plius AMD dabar netoli pagal spartą. Pas Nvidia efektyvumo šuolis turėtų būti labai didelis.
tas ir yra kad AMD lipa ant kulnu del to jau px ir optimizacija del el sanaudu teko skaityti kad ir AMD emesi tokios taktikos nes Nv taip daro ir nenori atsilikti hmm taigi tokia konkurencija kuris tures didesnis el sunaudojimo ir efektyvumo E peny mums naudojam ne visai i nauda ypac kai visur taip el brangsta.